
|
|
Today we announce a set of adaptation options for Amazon Nova in Amazon Sagemaker AI. Customers can now adapt Nova Micro, Nova Lite and Nova Pro throughout the model’s life cycle, including pre -training, under the supervision of fine fine -tuning and alignment. These techniques are available as recipes for Amazon Sagemaker with ready to use with trouble -free deployment to Amazon Bedrock, which supports both on request and commission permeability.
Amazon Nova Foundation models supply various generative cases of AI use across industries. Since customers of a range of deployment need models that reflect ownership, workflows and brand requirements. For rapid optimization and search-aurated generation (rag), they work well to integrate generally efficient endowment models into applications, but the workflows of critical business require the model to fit the model to meet specific accuracy, costs and latency requirements.
Choosing the correct technique of customization
The Amazon Nova models support a number of adaptation techniques including: 1) under the supervision of fine fine -tuning, 2) alignment, 3) continuing before training and 4) distillation of knowledge. The optimal choice depends on the targets, the complexity of the case of use and the availability of data and the calculation of resources. You can also combine multiple techniques to achieve your desired results with a preferred combination of performance, cost and flexibility.
Overseeed fine fine -tuning (SFT) It adapts the model parameters using the data set of training pairs input outputs specific to your target tasks and domains. Select from the following two implementation approaches based on data and cost volume:
- Fine fine -tuning (PEFT) -Itualizes only the subgroup of the model parameters through layers of light adapters such as Lora (low value adaptation). It offers faster training and lower calculation costs compared to complete fine -tuning. NOVA models adapted to PEFT are imported into Amazon Bedrock and induced by inference on request.
- Complete fine -tuning (FFT) – updates all model parameters and is ideal for scenarios if you have extensive data sets (tens of thousands of records). Novo models adapted via FFT can also be imported into Amazon Bedrock and caused to conclude with the permeability provided.
Alignment It controls the output of the model towards the required preferences for the needs and behavior of the product specific, such as the requirements for the company brand and customer experience. These preferences can be coded in several ways, including empirical examples and politicians. Nova models support two preference leveling techniques:
- Optimization of direct preference (DPO) – offers a direct way to tune the outputs of the model using preferred/not preferred pairs of answers. DPO learns from comparative preferences and optimizes outputs for subjective requirements such as tone and style. The DPO offers both the effective parameter and the full model version. The version effective parameters support inference on request.
- Proximal Optimization of Policy (PPO) – uses strengthening learning to increase the behavior of the model optimization for the required rewards such as usefulness, safety or connection. The reward model leads to optimize output scoring and helps the model to learn effective behavior while maintaining previously learned abilities.
Continuing pre -training (CPT) It extends the knowledge of the basic model through a separate adolescent learning about large number of unmarked proprietary data, including internal documents, transcripts and content specific to business. CPT followed by SFT and alignment via DPO or PPO provides a comprehensive way to customize new models for your applications.
Knowledge of knowledge It transmits knowledge from a larger model of the “teacher” to a smaller, faster and more cost -effective “student” model. Distillation is useful in scenarios where customers do not have sufficient samples of reference input-access and can use a more powerful model to expand training data. This process creates adapted accuracy model at a teacher level for specific cases and cost efficiency and speed at the level of students.
Here is a table summarizing available techniques of adaptation across different modalities and deployment options. Each technique offers specific training and inference capabilities depending on your implementation requirements.
| Recipe | Modality | Training | Derivation | ||
|---|---|---|---|---|---|
| Amazon Bedrock | Amazon Sagemaker | Amazon Bedrock on-Demand | Amazon Bedrock provided permeability | ||
| Under the supervision of fine tuning | Text, picture, video | ||||
| Fine fine -tuning (PEFT) | ✅ | ✅ | ✅ | ✅ | |
| Tuning | ✅ | ✅ | |||
| Optimization of direct preference (DPO) | Text, picture | ||||
| Parameter-effective DPO | ✅ | ✅ | ✅ | ||
| The entire DPO model | ✅ | ✅ | |||
| Proximal Optimization of Policy (PPO) | Only the text | ✅ | ✅ | ||
| Continuous pre -training | Only the text | ✅ | ✅ | ||
| Distillation | Only the text | ✅ | ✅ | ✅ | ✅ |
Early access customers, including Cosine AI, Massachusetts Institute of Technology (MIT) Computer Science and Artificial Intelligence Laboratory (CSail), Volkswagen, Amazon Customer Service and Amazon Catalog Systems Service.
Customize Novo Models in Action
The following goes through an example of Nova Micro’s adaptation by optimizing direct preference on an existing data set of preferences. If you want to do it, you can use the Amazon Sagemaker Studio.
Start your Sagemaker studio in the Amazon Sagemaker AI and choose JumpMachine learning hub (ML) with foundation models, built -in algorithms and pre -created ml solutions that you can deploy several clicks.
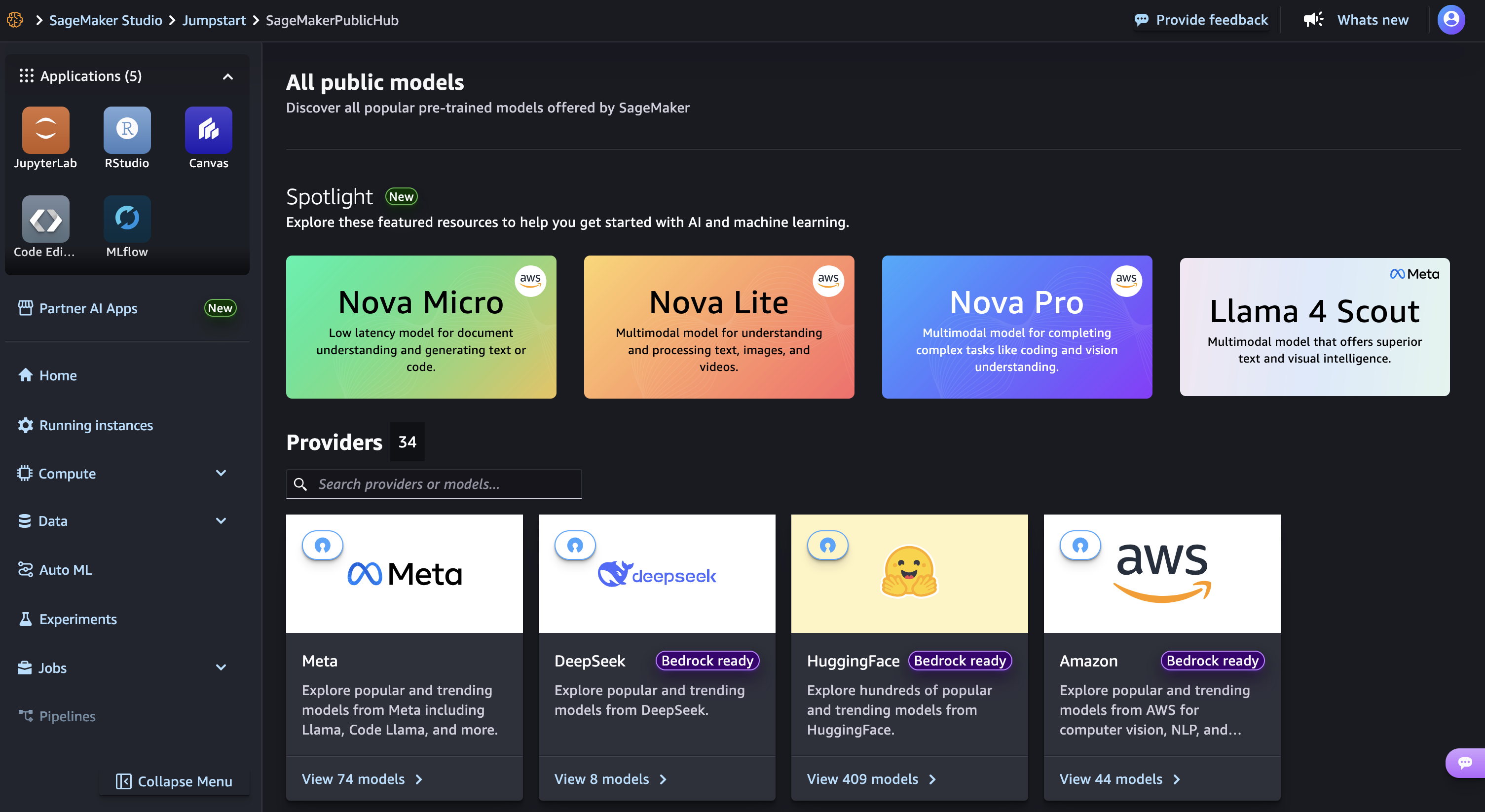
Then choose Nova microModel only for text that provides the lowest latency responses for the lowest cost of inference between the Nova Model Family, and then select Train.
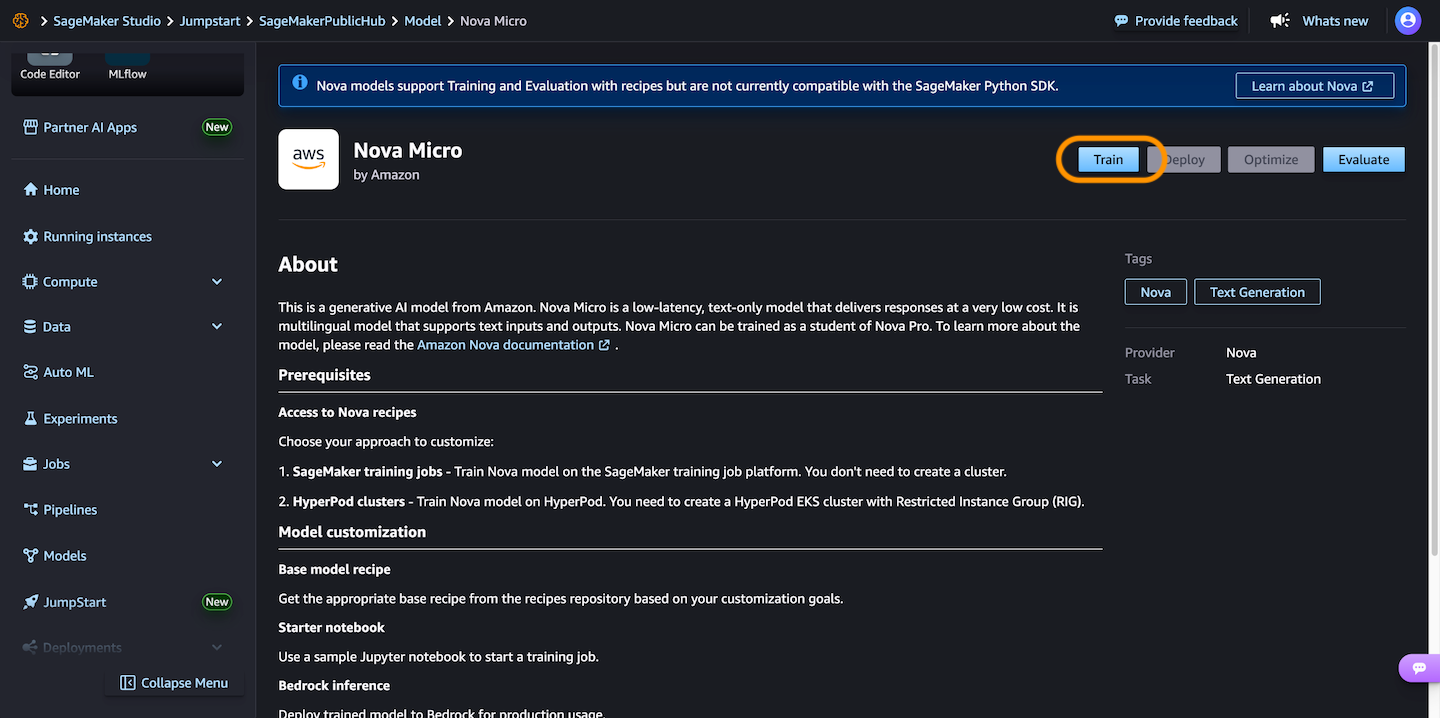
You can also choose a tuning Recipe for training model with marked data to increase performance on specific tasks and alignment with the desired behavior. Selection Optimization of direct preference It offers a direct way to tune the model outputs with your preferences.
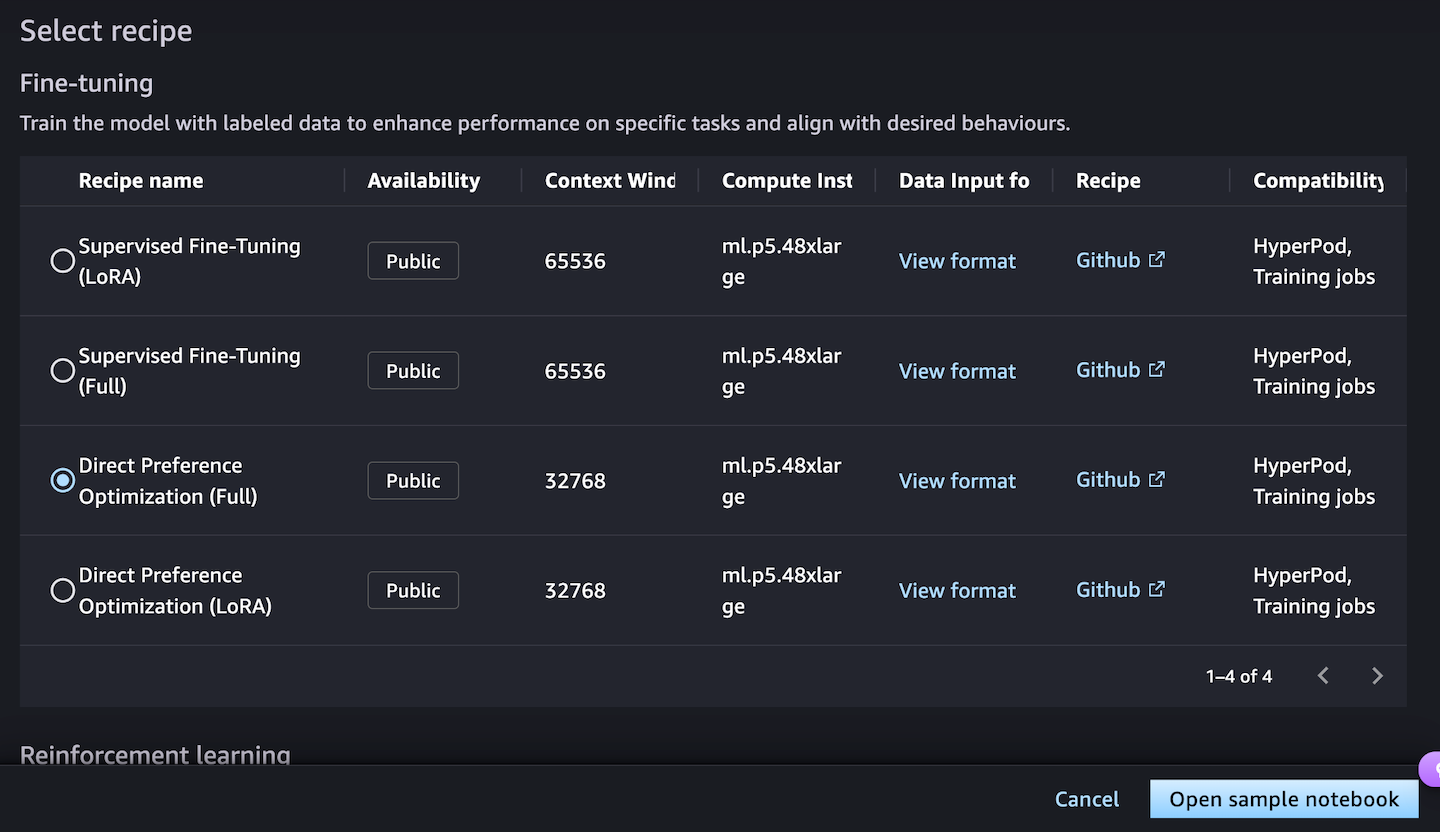
When you decide An open sample notebookYou have two options to run a recipe: either on Sagemaker or Hyperpod Sagemaker:
Choose Start the recipe on Sagemaker Training Jobs If you do not have to create a cluster and train the model using a sample notebook by selecting JupyterLab space.
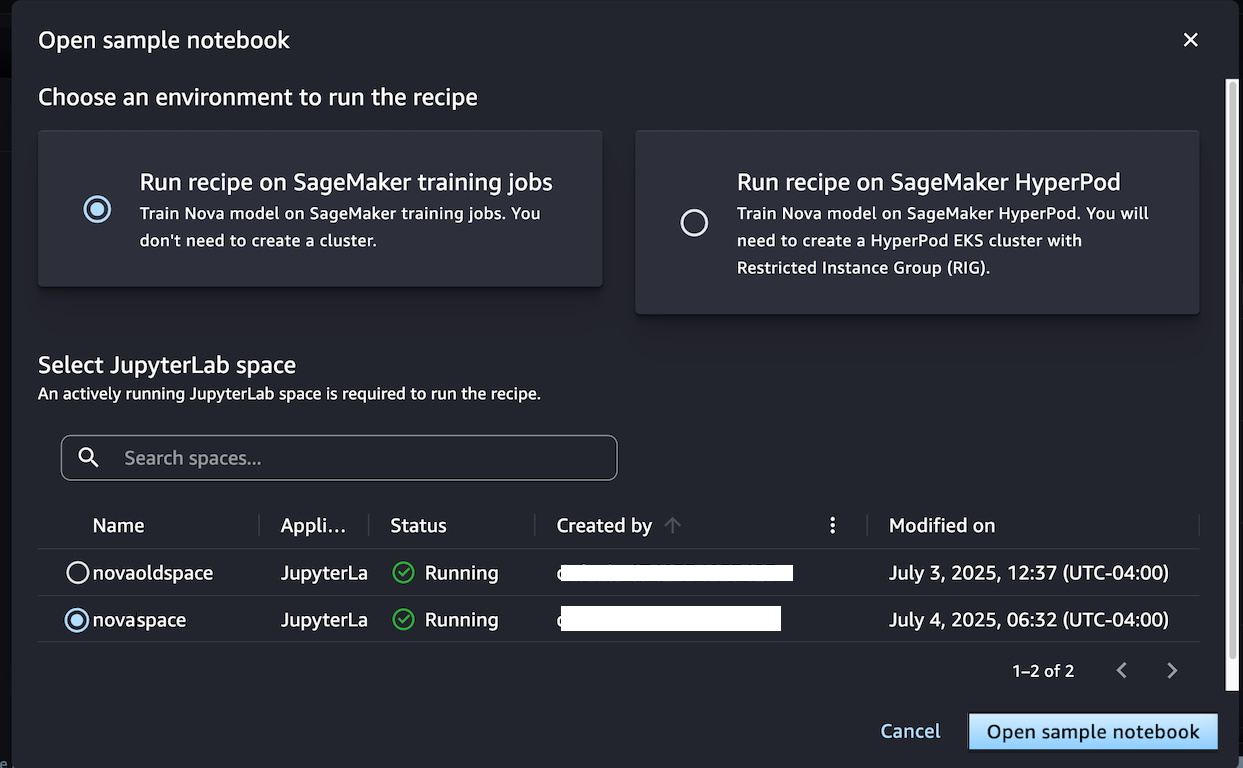
Alternatively, if you want to have a permanent cluster environment optimized for iterative training processes, choose Start the recipe for Sagemaker Hyperpod. You can choose the Hyperpod ECS cluster with at least one group of limited instances (RIG) to provide a specialized isolated environment that is required for such training NOVA model. Then select your Jupyterlabspace and An open sample notebook.
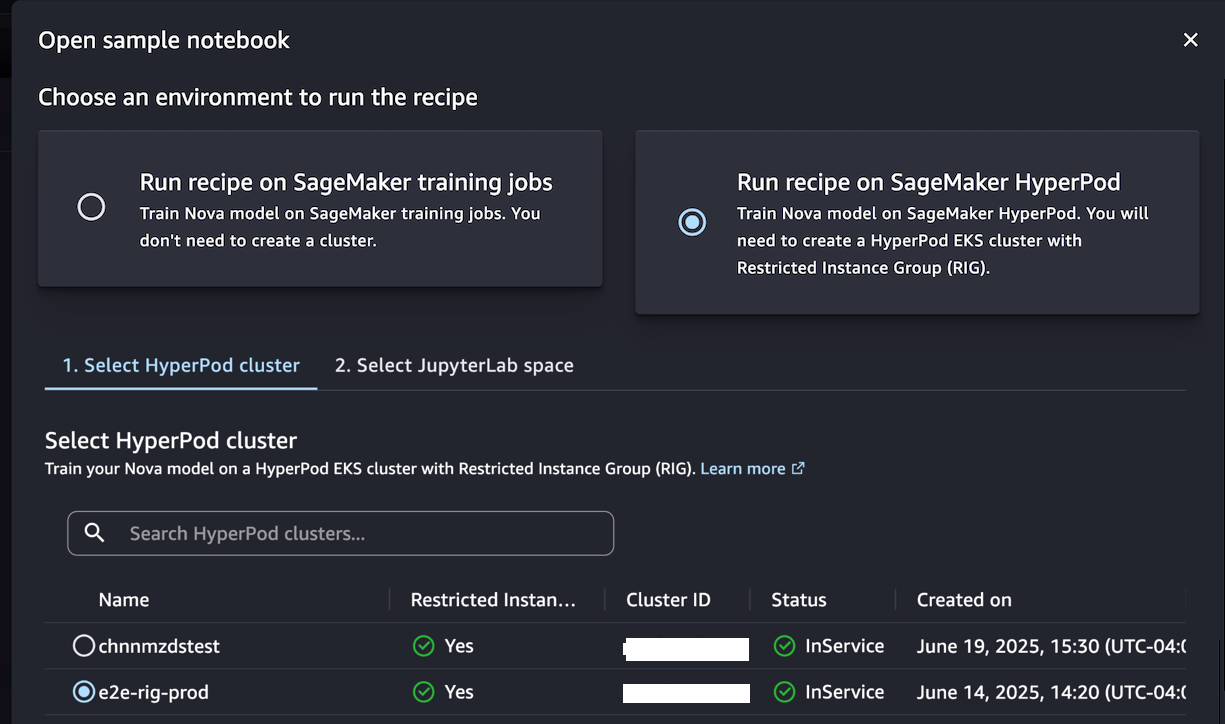
This notebook provides an end-to-end pass to create a Hyperpod Sagemaker task using the Sagemaker Nova with a recipe and to conclude. With the Sagemaker Hyperpod recipe, you can streamline comprehensive configurations and smoothly integrate data sets for optimized training.
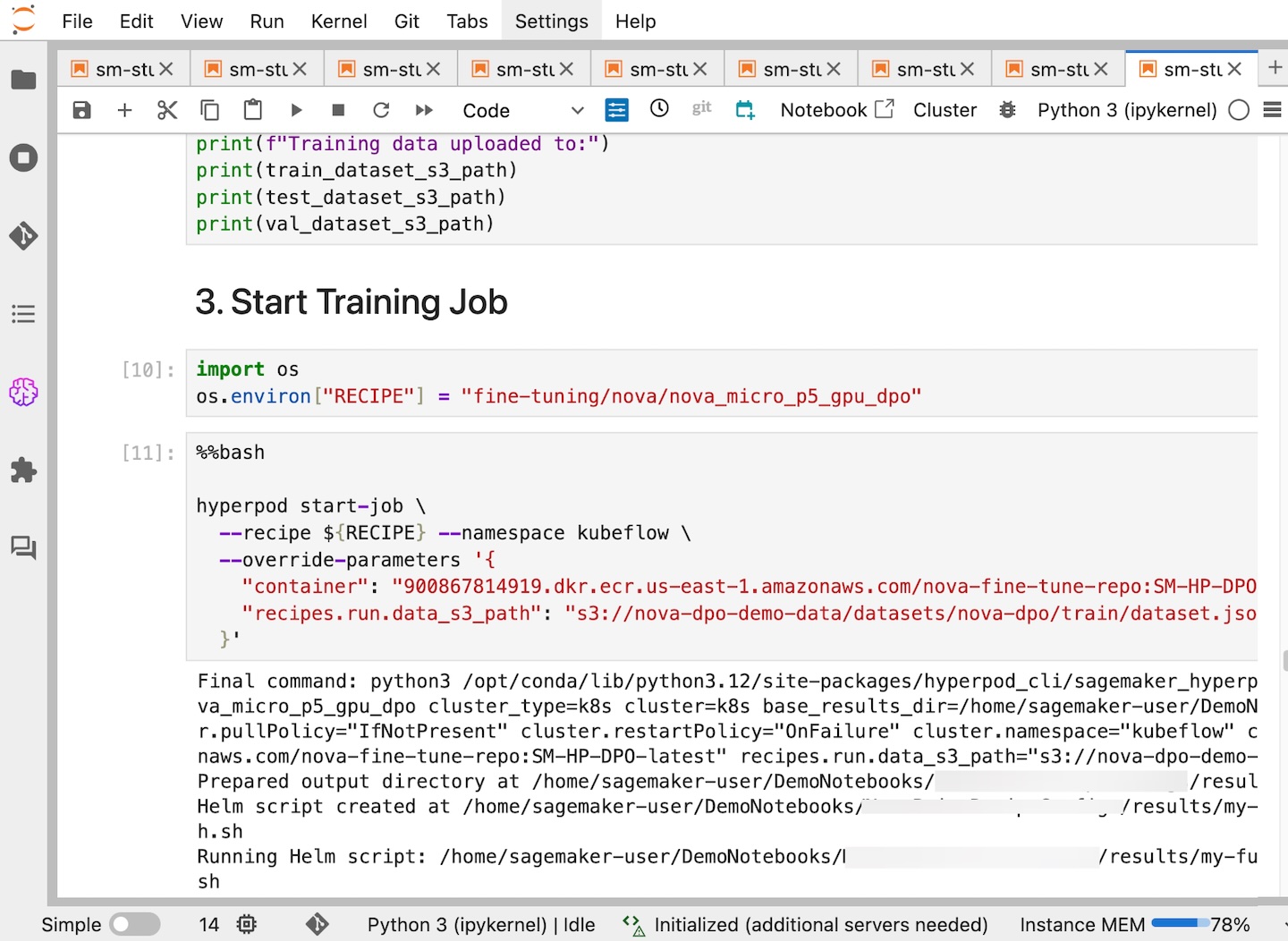
In the Sagemaker Studio you can see that your role Hyperpod Sagemaker has been successfully created and you can follow it for further progress.
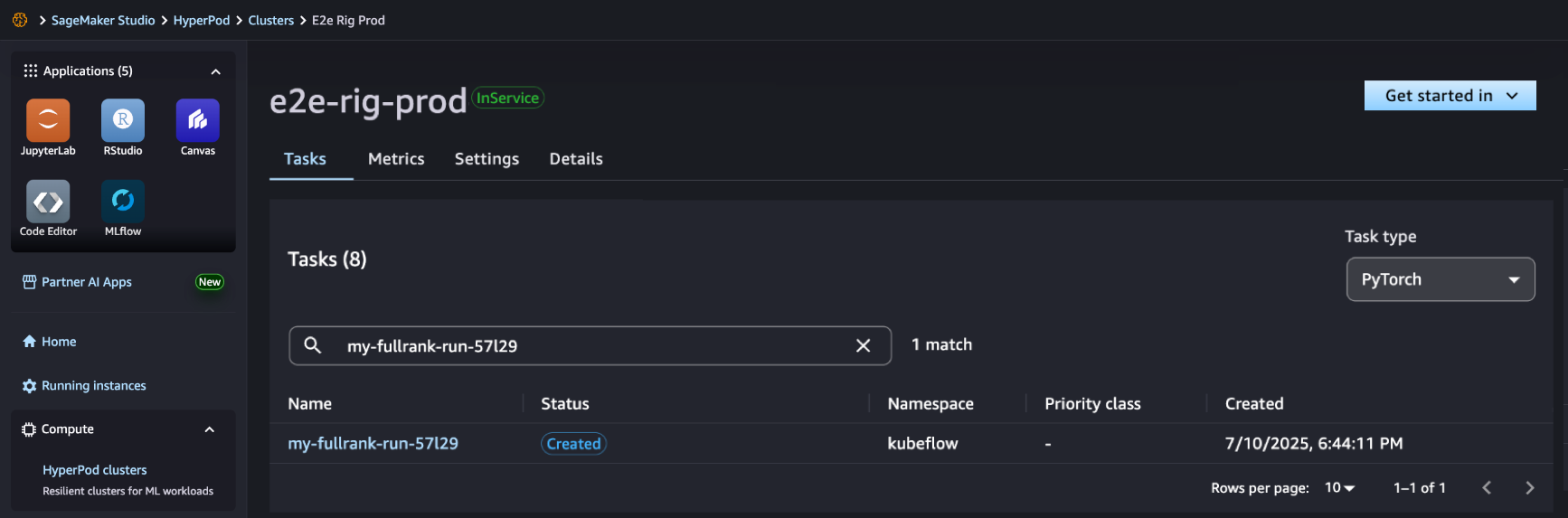
After completing the work, you can use a benchmark recipe to evaluate whether the adapted model works better with the agent tasks.
Complex documentation and other examples of implementation can be found on the Hyperpod Sagemaker reception storage on Github. We continue to expand the recipes based on feedback from customers and emerging ML trends, ensuring that you have the tools needed to adjust the AI model.
Availability and start
Recipes for Amazon Nova for Amazon Sagemaker AI are available on US East (N. Virginia). For more information about this feature, visit the Amazon Nova and Amazon Nova website and start in the Amazon Sagemaker AI Console.
–Betty
Updated July 16, 2025 – Revised Table and Console Screen Data.